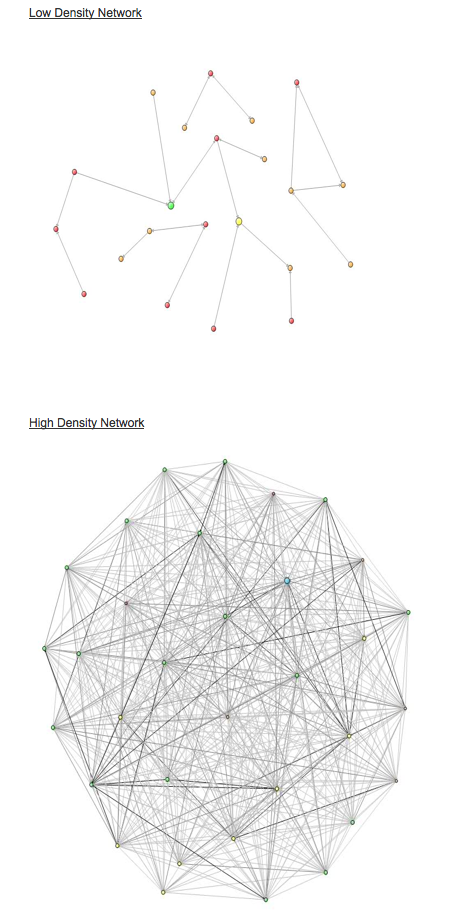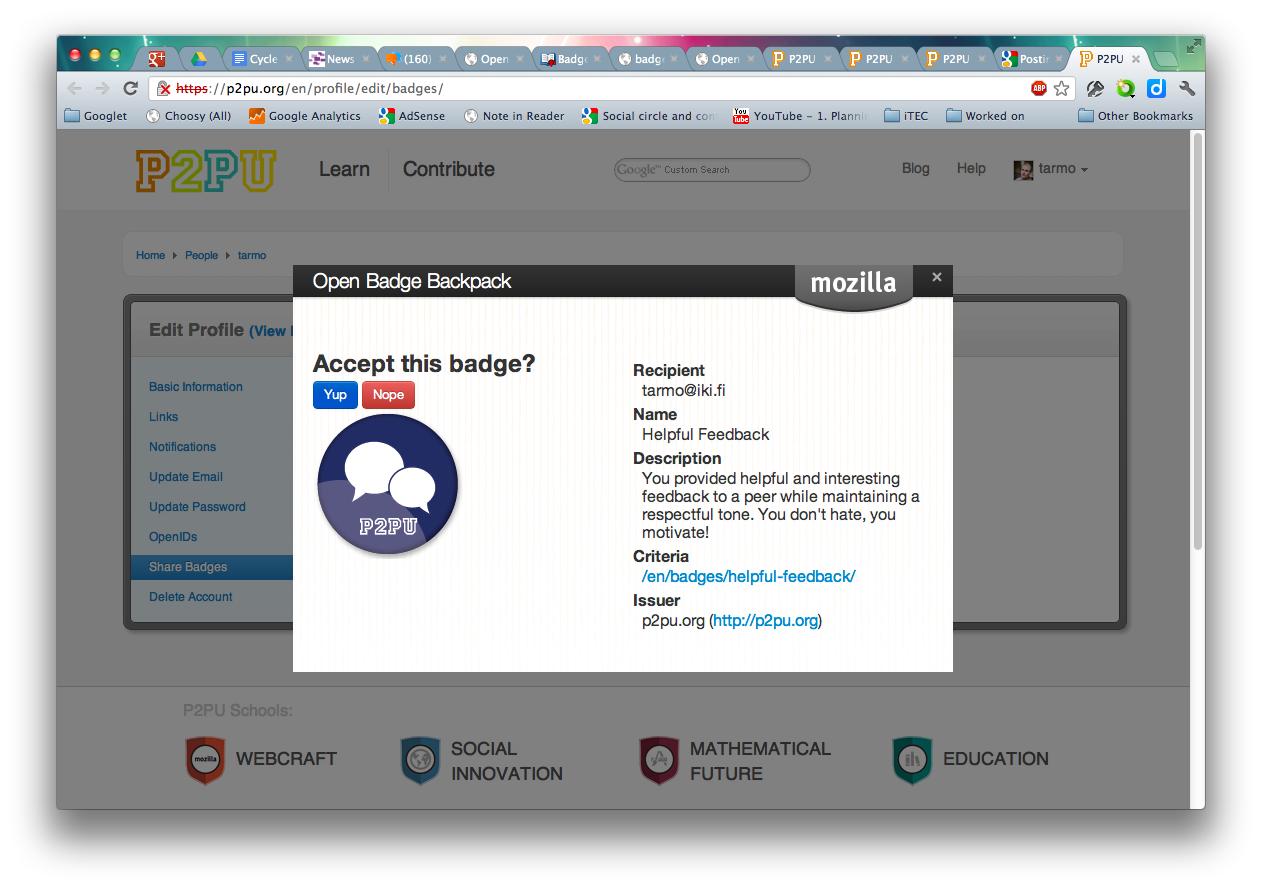
I've mentioned Open Badges earlier this year. It's an open standard proposal by the Mozilla Foundation that attempts to create a web-based way for anyone (or any institution) to give accreditation to …
Continue Reading about Open Badges, current state of development →